Integrating Kafka with ClickHouse Cloud
Introduction
ClickPipes is a managed integration platform that makes ingesting data from a diverse set of sources as simple as clicking a few buttons. Designed for the most demanding workloads, ClickPipes's robust and scalable architecture ensures consistent performance and reliability.
Creating your first ClickPipe
Access the SQL Console for your ClickHouse Cloud Service.
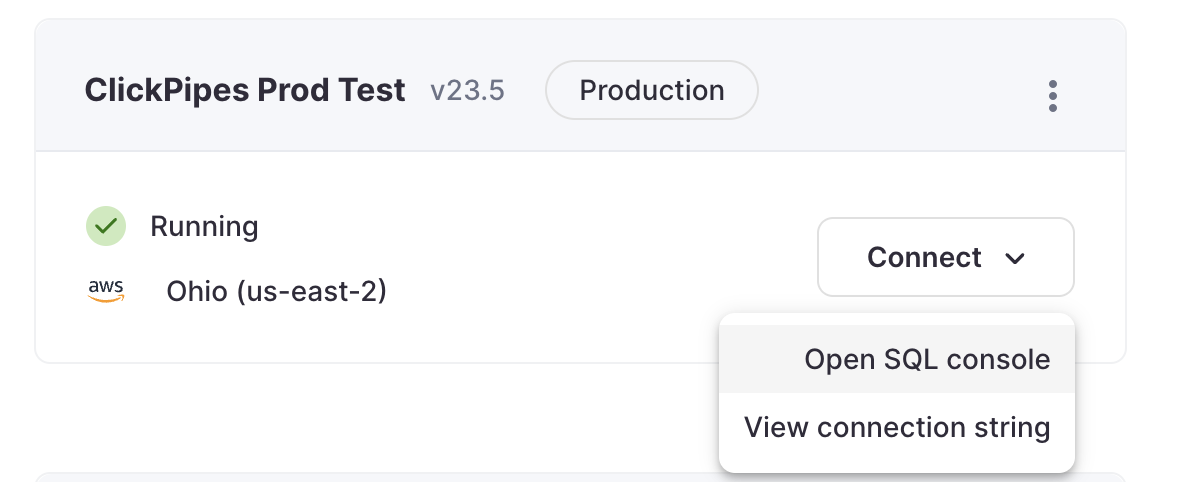
Select the
Importsbutton on the left-side menu and click on "Ingest Data From Kafka"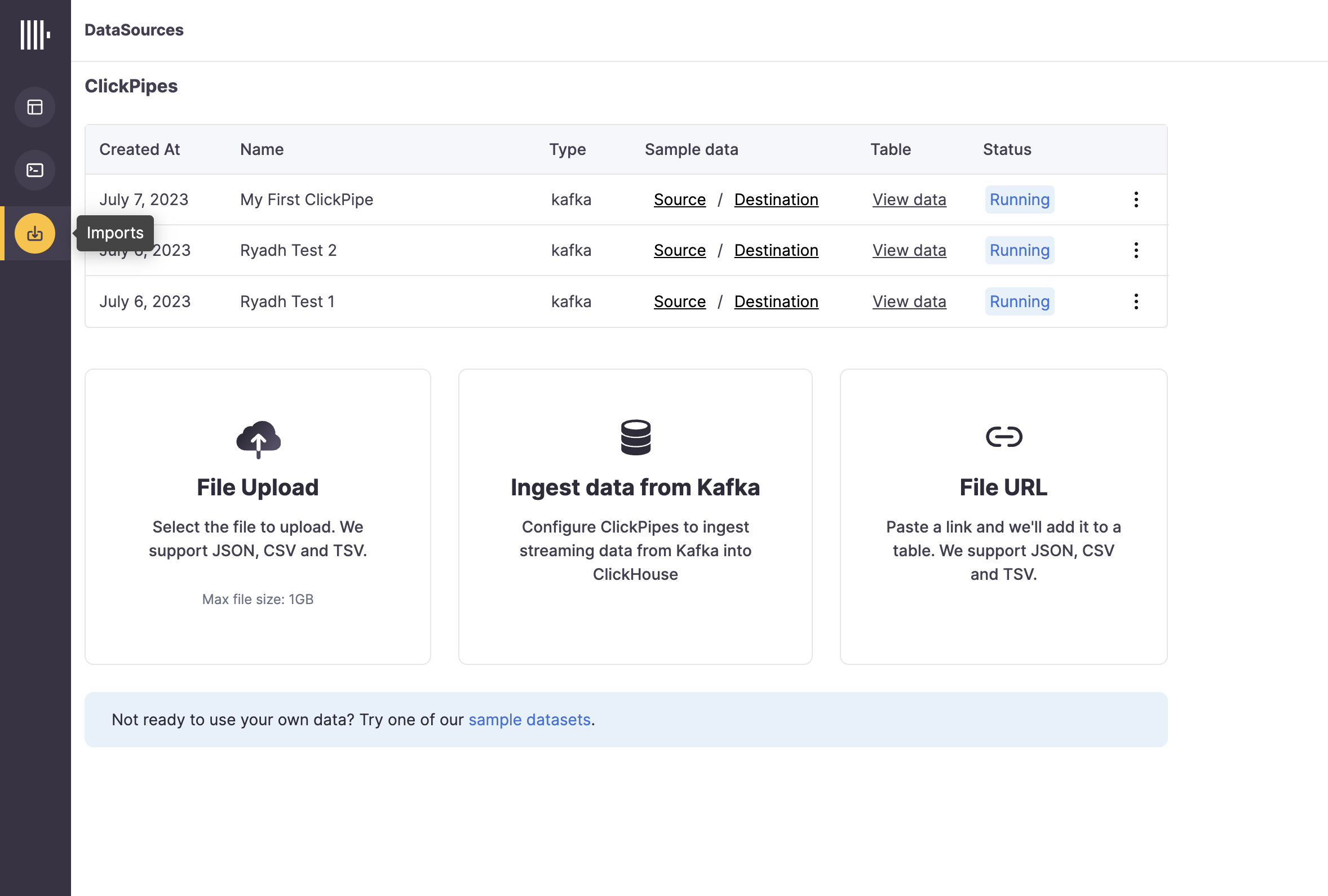
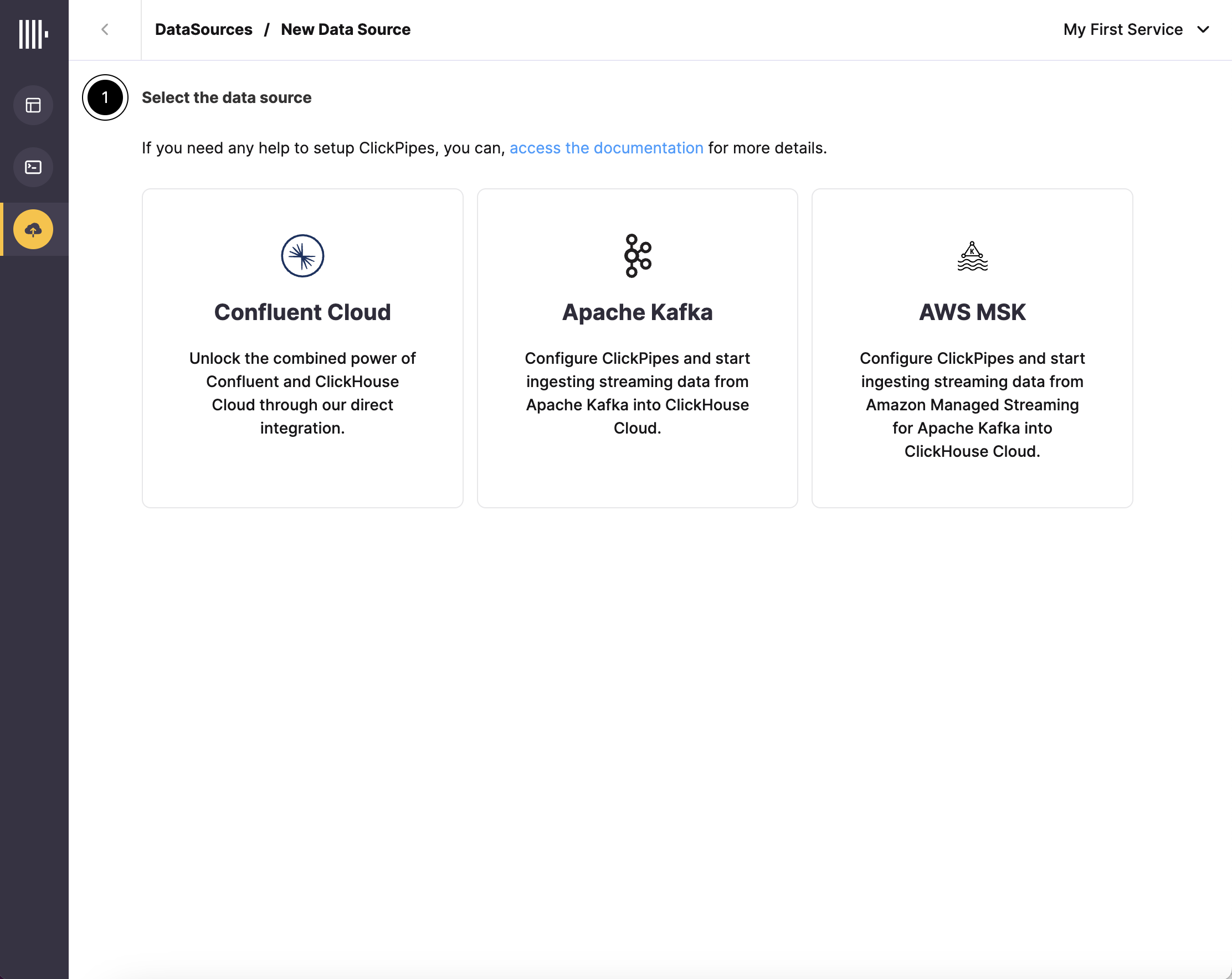
Select your data source, either "Confluent Cloud", "Apache Kafka", or "AWS MSK"
Fill out the form by providing your ClickPipe with a name, a description (optional), your credentials, a consumer group as well as the Kafka broker URL. Optionally you can also select a Schema Registry server and credentials to handle your decoding and validation (Currently only available for Confluent Cloud)
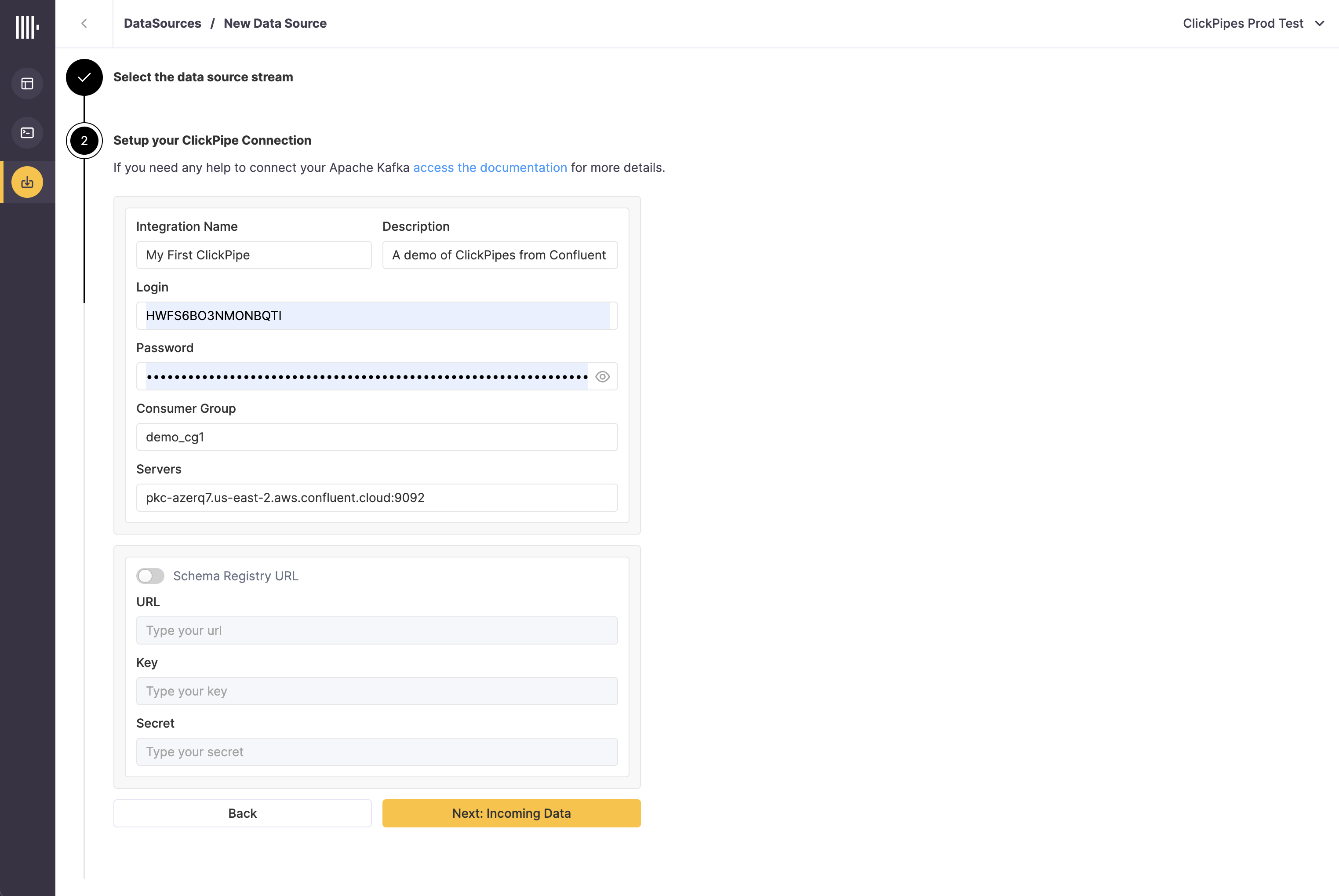 note
noteAWS MSK authentication currently only supports SCRAM-SHA-512 authentication, IAM authentication is coming soon
4a. Optional for Schema Registry: Specify the complete URL of your Schema Registry server along with the precise RESTful path to the ID representing your preferred schema document. This schema will serve as the validation benchmark for all messages from your topic, consequently blocking any messages that fail the validation against the designated schema. Additionally, the Schema Registry allows new schema retreival via JSON_SR messages. In scenarios where your JSON_SR message carries a Schema Registry ID differing from the current one, Clickpipes will fetch the corresponding schema and use it for future validation.
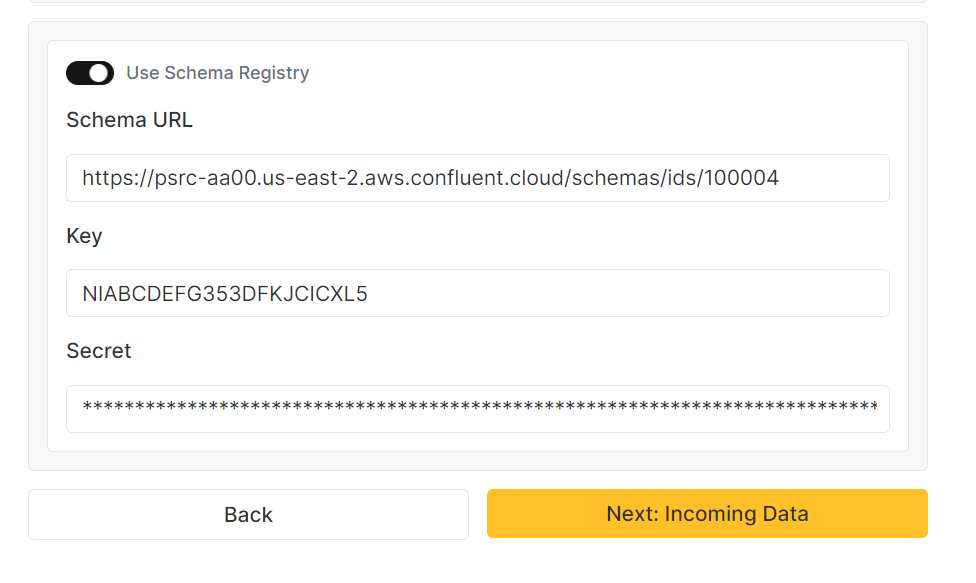
Currently only JSON format is supported for Schema Registry. Additionally, Schema references are not supported.
Select your data format (we currently support
JSON), and your Kafka topic. The UI will display a sample document from the selected Kafka topic.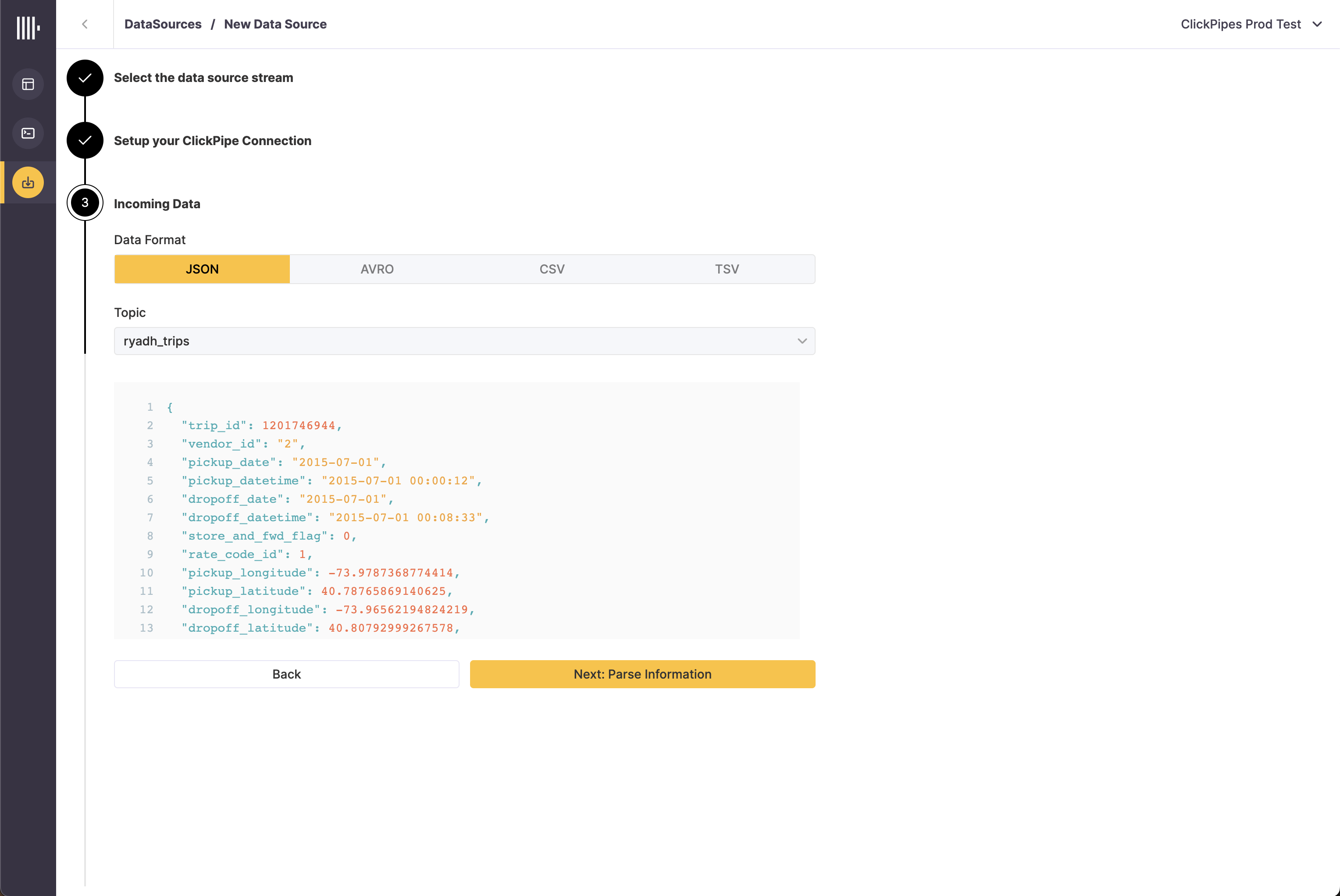
In the next step, you can select whether you want to ingest data into a new ClickHouse table or reuse an existing one. Follow the instructions in the screen to modify your table name, schema, and settings. You can see a real-time preview of your changes in the sample table at the top.
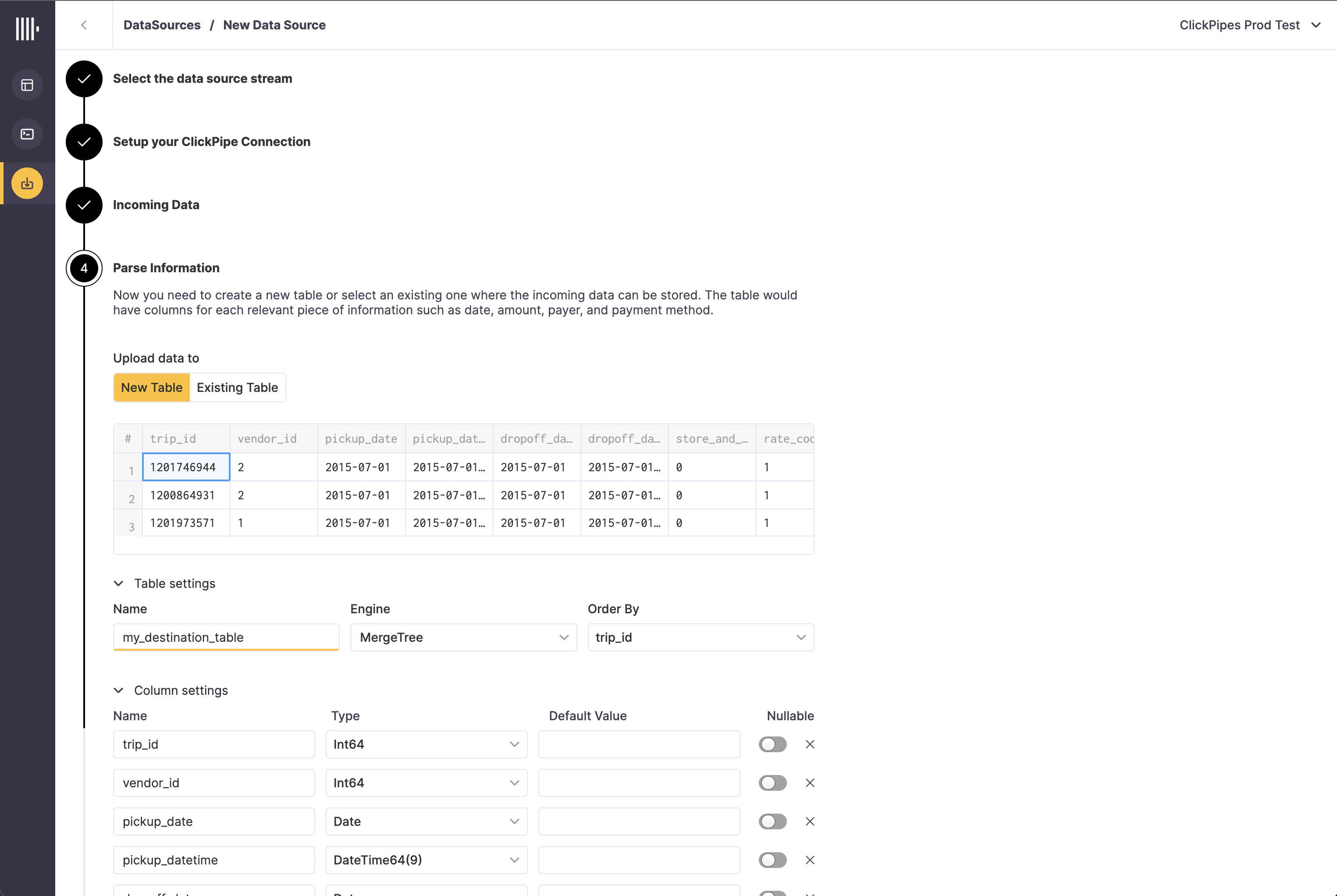
You can also customize the advanced settings using the controls provided

Alternatively, you can decide to ingest your data in an existing ClickHouse table. In that case, the UI will allow you to map fields from Kafka with the ClickHouse fields in the selected destination table.
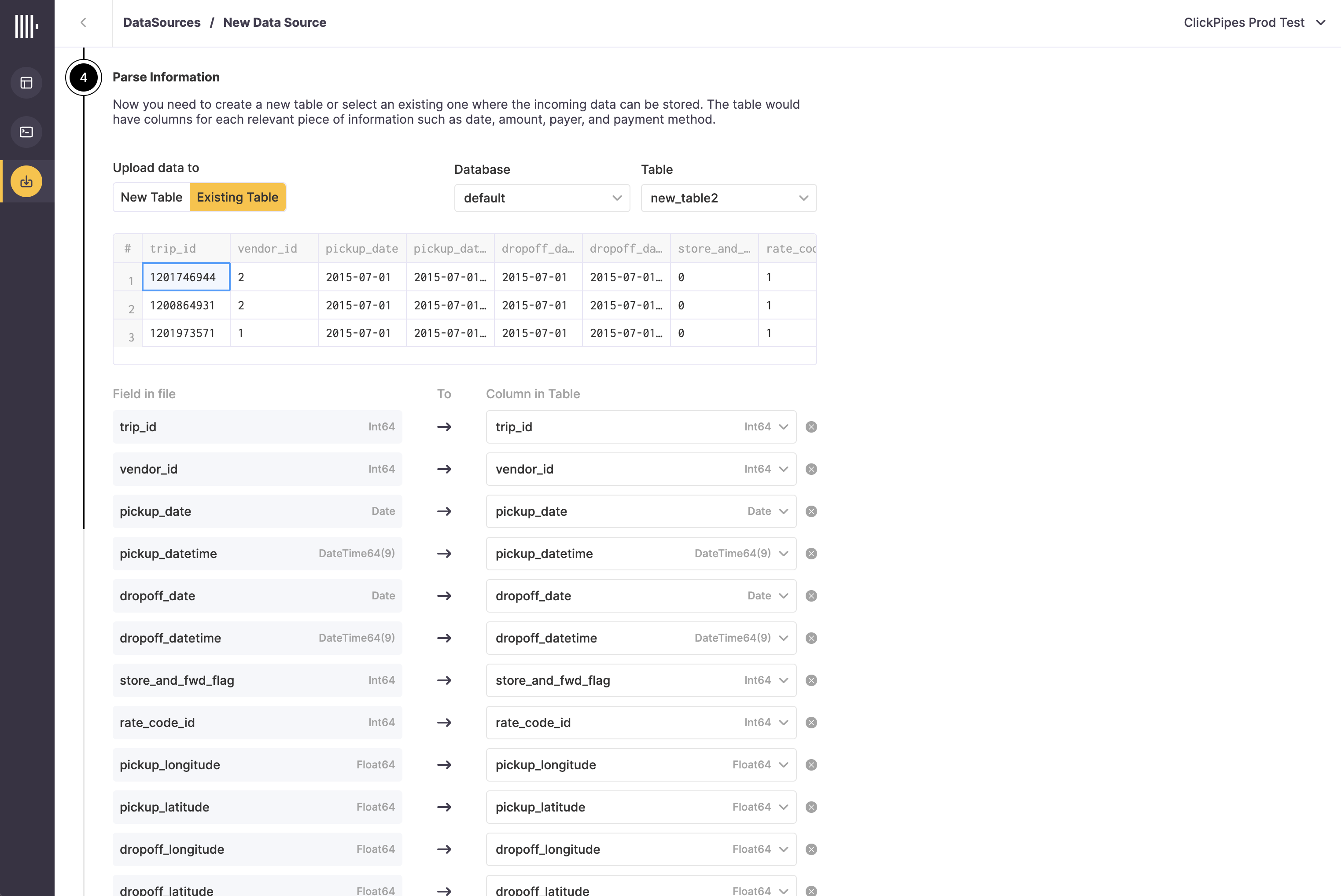
Finally, you can decide to enable the error logging table. When enabled, ClickPipes will create a table next to your destination table with the postfix
_clickpipes_error. This table will contain any errors from the operations of your ClickPipe (network, connectivity, etc.) and also any data that don't conform to the schema specified in the previous screen. The error table has a TTL of 7 days.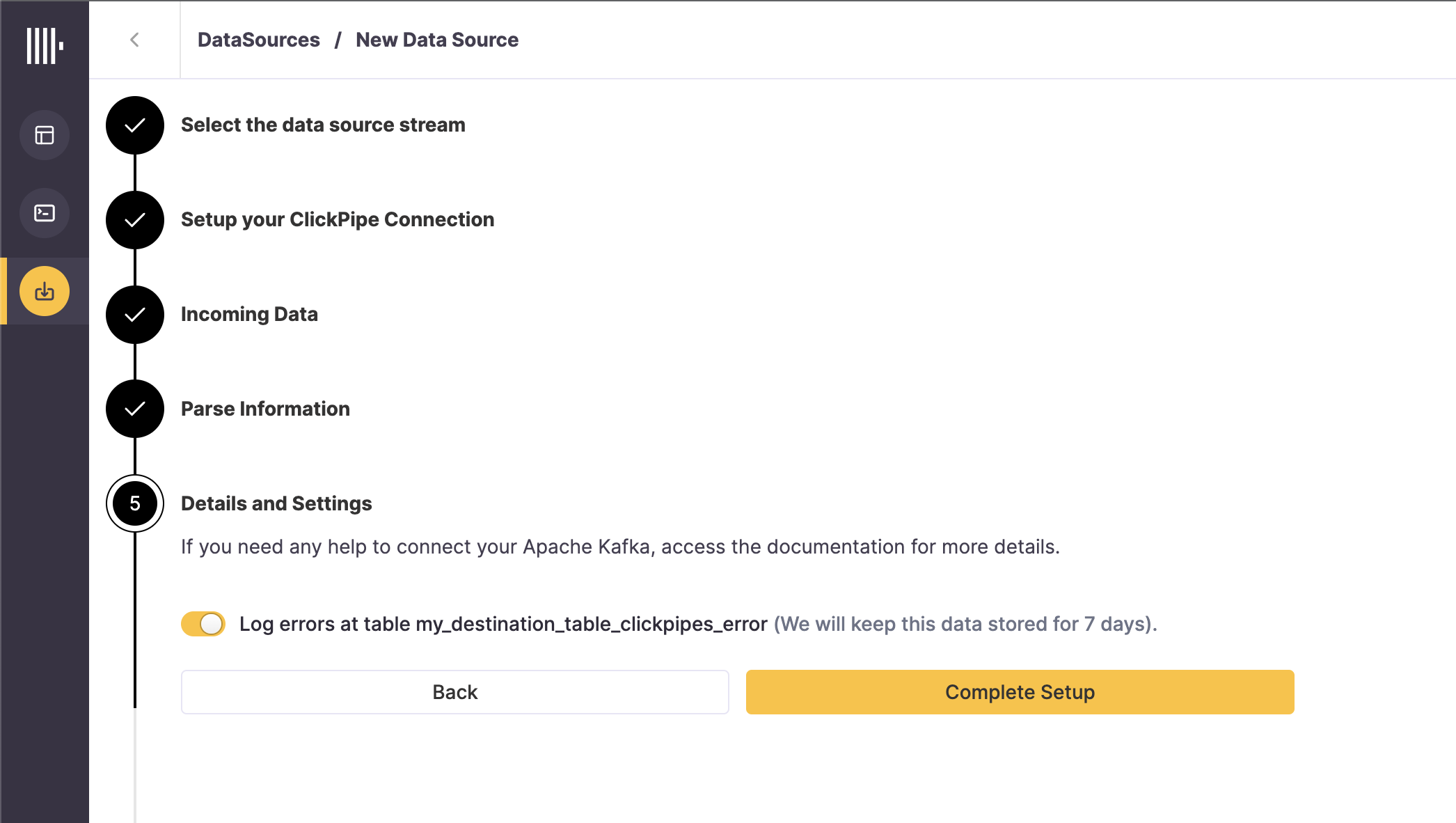
By clicking on "Complete Setup", the system will register you ClickPipe, and you'll be able to see it listed in the summary table.

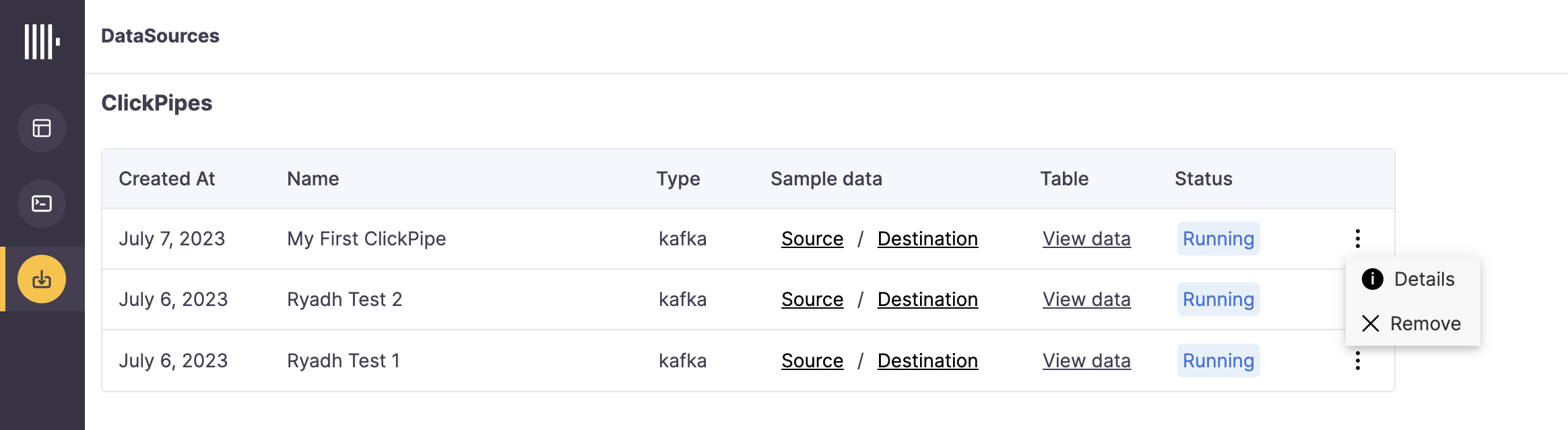
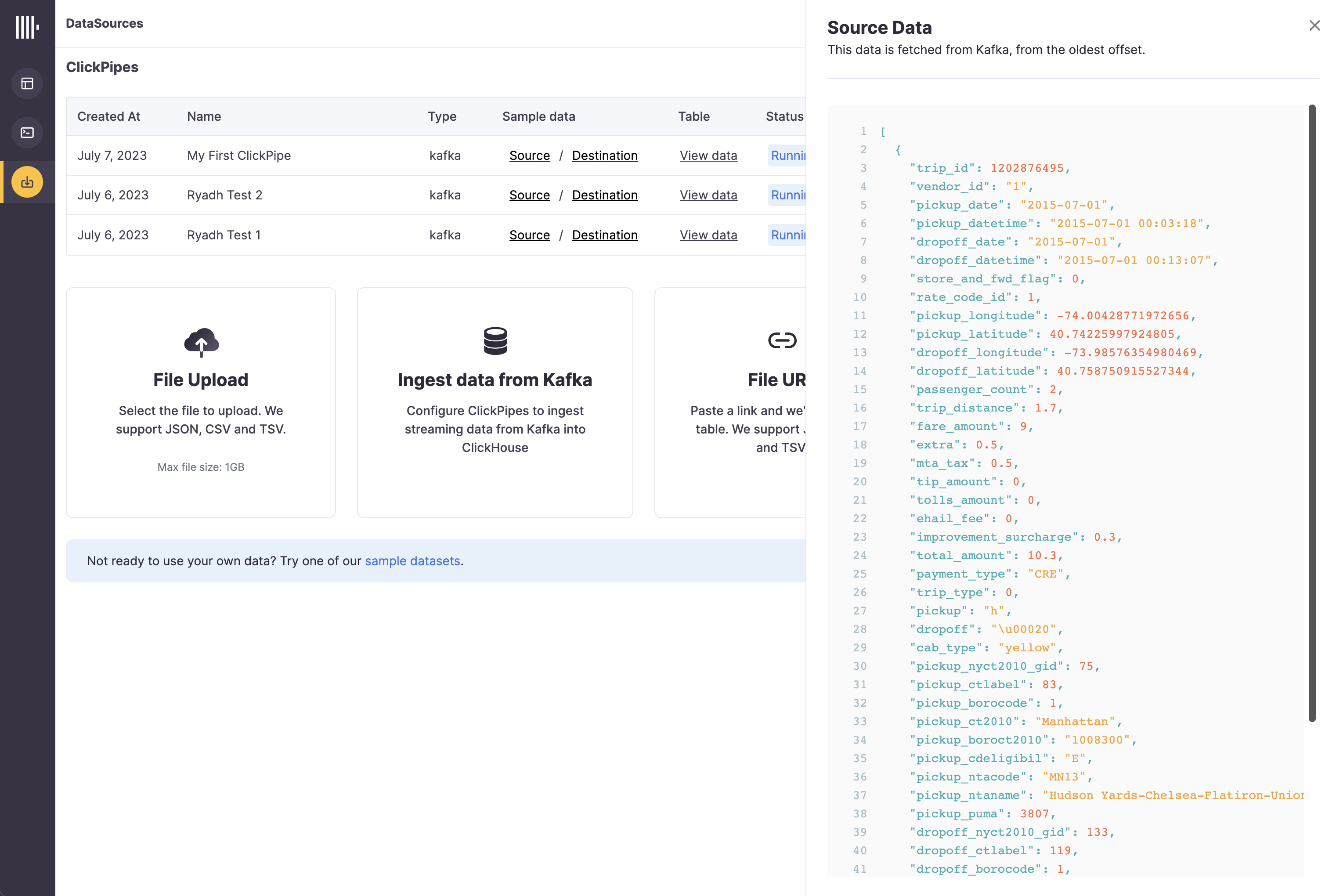
The summary table provides controls to display sample data from the Kafka broker or the destination table in ClickHouse
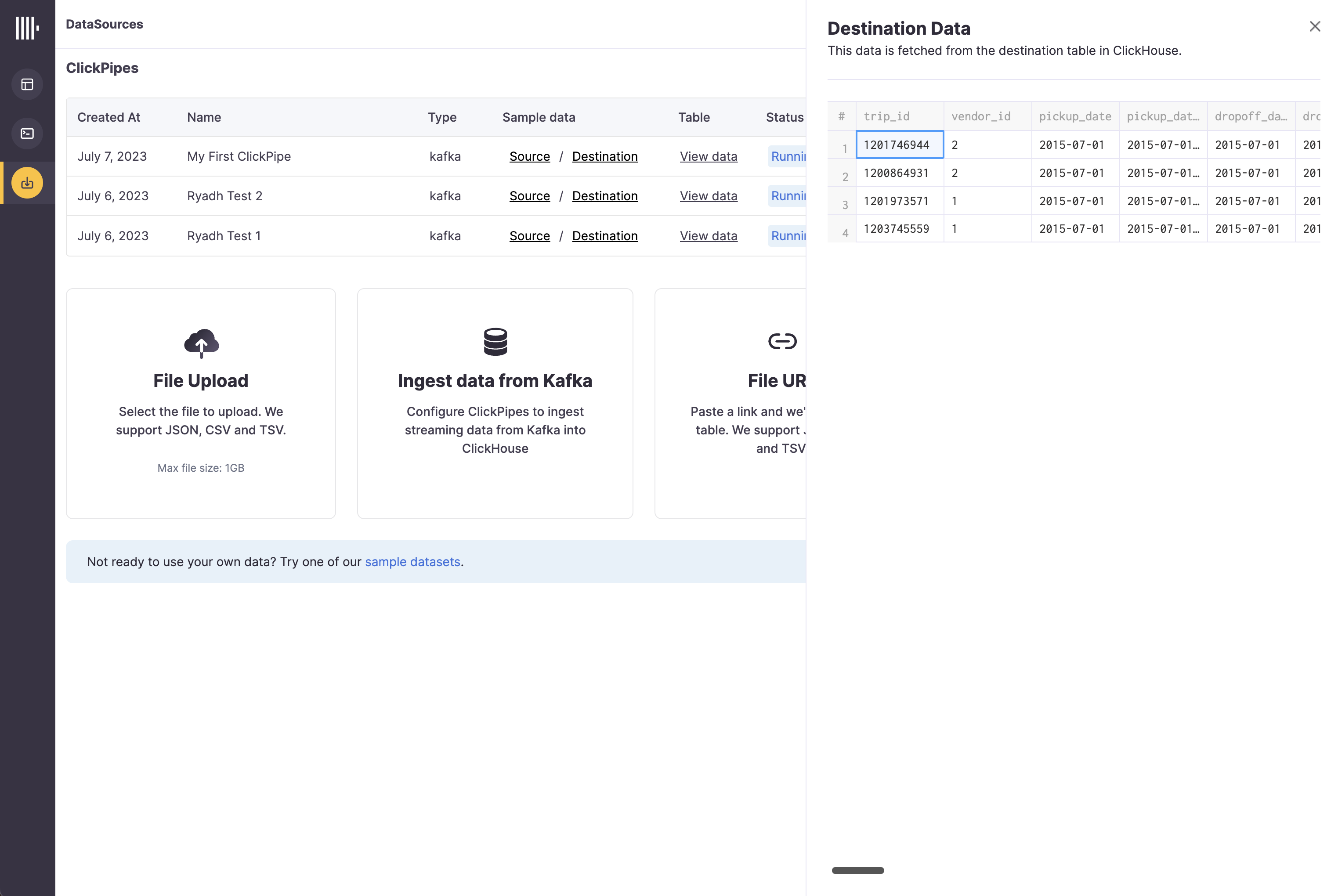
As well as controls to remove the ClickPipe and display a summary of the ingest job.
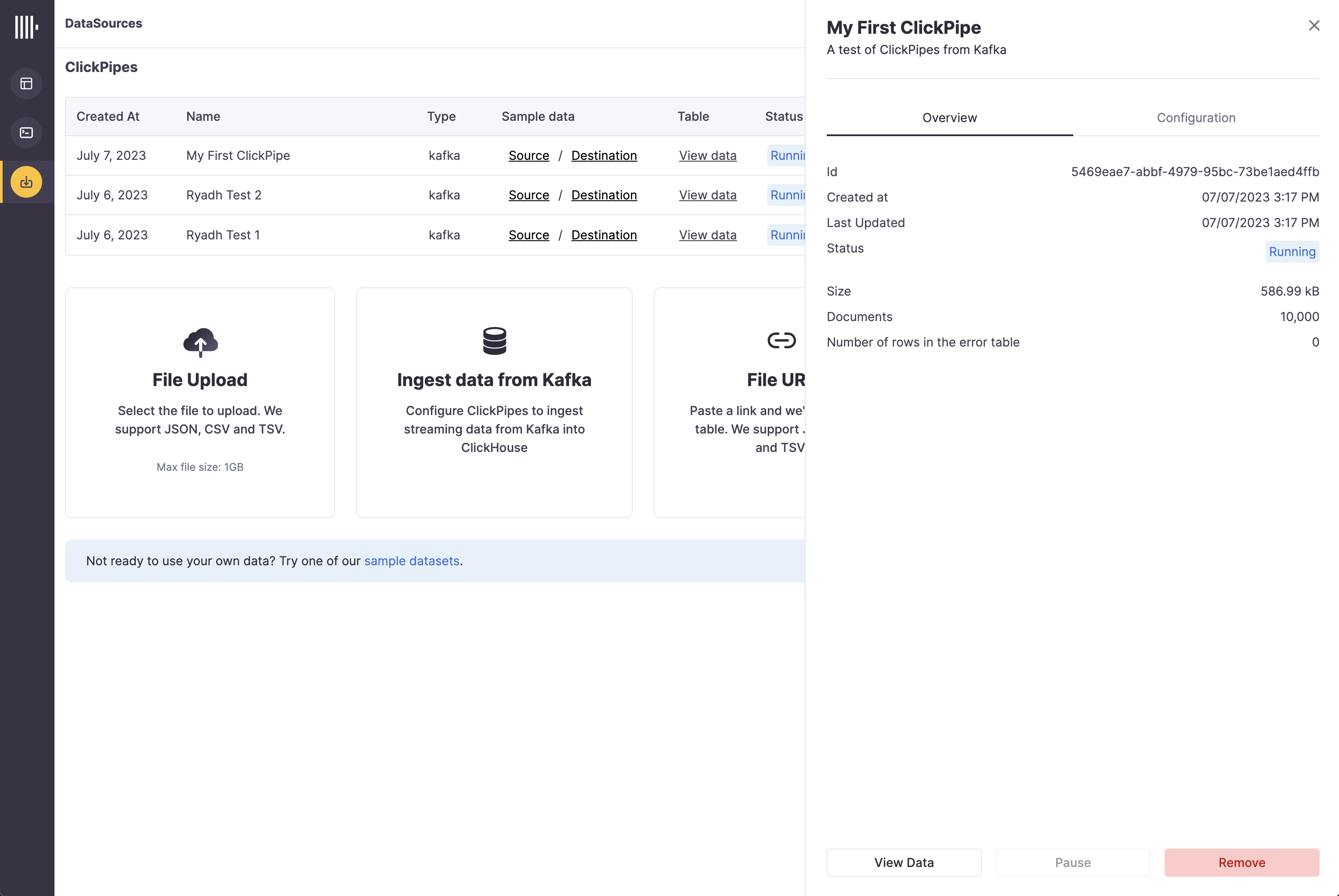
Congratulations! you have successfully set up your first ClickPipe. This job will be continuously running, ingesting data in real-time from your remote data source.
Supported Data Sources
| Name | Logo | Type | Description |
|---|---|---|---|
| Confluent Cloud | Streaming | Unlock the combined power of Confluent and ClickHouse Cloud through our direct integration. | |
| Apache Kafka | Streaming | Configure ClickPipes and start ingesting streaming data from Apache Kafka into ClickHouse Cloud. | |
| AWS MSK | Streaming | Configure ClickPipes and start ingesting streaming data from AWS MSK into ClickHouse Cloud. |
More connectors are will get added to ClickPipes, you can find out more by contacting us.
Supported data formats
The supported formats are:
| Format | Support |
|---|---|
| JSON | ✔ |
| AvroConfluent | Coming Soon |
| TabSeparated | Coming Soon |
| CSV | Coming Soon |
Supported data types
The following ClickHouse types are currently supported by the transform package (with standard JSON as the source):
- Base numeric types
- Int8
- Int16
- Int32
- Int64
- UInt8
- UInt16
- UInt32
- UInt64
- Float32
- Float64
- Boolean
- String
- FixedString
- Date, Date32
- DateTime, DateTime64
- Enum8/Enum16
- LowCardinality(String)
- Map with keys and values using any of the above types (including Nullables)
- Tuple and Array with elements using any of the above types (including Nullables, one level depth only)
- JSON/Object('json'). experimental
Nullable versions of the above are also supported with these exceptions:
- Nullable Enums are not supported
- LowCardinality(Nullable(String)) are not supported
Current Limitations
- During the Private Preview phase, ClickPipes is available only on the services backed by Amazon Web Services, in the
us-east-2andeu-central-1regions. - Private Link support isn't currently available for ClickPipes but will be released in the near future.
List of Static IPs
The following are the static IPs that ClickPipes uses to connect to your Kafka brokers:
18.195.233.217, 3.127.86.90, 35.157.23.2, 3.131.130.196, 3.23.172.68, 3.20.208.150
F.A.Q
What is ClickPipes ?
ClickPipes is a ClickHouse Cloud feature that makes it easy for users to connect their ClickHouse services to external data sources, specifically Kafka. With ClickPipes for Kafka, users can easily continuously load data into ClickHouse, making it available for real-time analytics.
What types of data sources does ClickPipes support ?
Currently, ClickPipes supports Confluent Cloud, AWS MSK, and Apache Kafka as data sources. However, we are committed to expand our support for more data sources in the future. Don't hesitate to contact us if you want to know more.
How does ClickPipes for Kafka work ?
ClickPipes uses a dedicated architecture running the Kafka Consumer API to read data from a specified topic and then inserts the data into a ClickHouse table on a specific ClickHouse Cloud service.
What's the difference between ClickPipes and the ClickHouse Kafka Table Engine?
The Kafka Table engine is a ClickHouse core capability that implements a “pull model” where the ClickHouse server itself connects to Kafka, pulls events then writes them locally.
ClickPipes is a separate cloud service that runs independently from the ClickHouse Service, it connects to Kafka (or other data sources) and pushes events to an associated ClickHouse Cloud service. This decoupled architecture allows for superior operational flexibility, clear separation of concerns, scalable ingestion, graceful failure management, extensibility and more.
What are the requirements for using ClickPipes for Kafka ?
In order to use ClickPipes for Kafka, you will need a running Kafka broker and a ClickHouse Cloud service with ClickPipes enabled. You will also need to ensure that ClickHouse Cloud can access your Kafka broker. This can be achieved by allowing remote connection on the Kafka side, whitelisting ClickHouse Cloud Egress IP addresses in your Kafka setup. Support for AWS Private Link is coming soon.
Can I use ClickPipes for Kafka to write data to a Kafka topic ?
No, the ClickPipes for Kafka is designed for reading data from Kafka topics, not writing data to them. To write data to a Kafka topic, you will need to use a dedicated Kafka producer.
What data formats are supported by ClickPipes for Kafka ?
The list of supported data types is displayed above.
Does ClickPipes support data transformation ?
Yes, ClickPipes supports basic data transformation by exposing the DDL creation. You can then apply more advanced transformations to the data as it is loaded into its destination table in a ClickHouse Cloud service leveraging ClickHouse's materialized views feature.
What delivery semantics ClickPipes for Kafka supports ?
ClickPipes for Kafka provides
at-least-oncedelivery semantics (as one of the most commonly used approaches). We'd love to hear your feedback on delivery semantics (contact form). If you need exactly-once semantics, we recommend using our officialclickhouse-kafka-connectsink.Is there a way to handle errors or failures when using ClickPipes for Kafka ?
Yes, ClickPipes for Kafka will automatically retry case of failures when consuming data from Kafka. ClickPipes also supports enabling a dedicated error table that will hold errors and malformed data for 7 days.
Does using ClickPipes incur an additional cost ?
ClickPipes is not billed separately at the moment. Running ClickPipes might generate an indirect compute and storage cost on the destination ClickHouse Cloud service like any ingest workload.
What authentication mechanisms are supported for ClickPipes for Kafka?
For Apache Kafka and Confluent Cloud data sourced, ClickPipes supports SASL/PLAIN authentication with TLS encryption. For Amazon MSK ClickPipes supports SCRAM-SHA-512 authentication.